Article by Benedikt S. Vogler and Gerhard Schwab
Article as PDF.
Abstract
A large amount of affordable, wearable medical and fitness devices have been developed since the beginning of the 2000s. This stems from the rapid improvements in technology and the decrease in price and size for batteries, microchips, and hardware, as well as huge advances in sensor technology. Medical data recorded by those devices contain intimate and personal information. We identify the chances and risks emerging from the availability of this data from an ethical point of view. We will discuss the up- and downsides of this technology, as well as taking into account the psychological effects these devices can have on their users.
Health Movements
The evolution of wearable medical and fitness devices around the turn of the millennium has given rise to some new social health movements. The term ”Quantified Self”, describes the idea ”that using wearable tech to collect detailed data about everything you do, eat and feel will reveal patterns and correlations that can help you improve your life.”[1] It is the foundation for the social movement bearing the same name. Applying the idea of this movement to one's life, people can be assisted in improving their quality of life by a myriad of tools that record their medical data. One has to note that the idea of ”Quantified Self” is therefore marketed by the firms selling those wearable medical and (mainly) fitness devices. To find patterns in the collected data, people either need assisting software, which is mostly provided by the producer of the wearable device or they need sound statistical skills themselves. However, revealing patterns is not the only reason that wearable medical and fitness devices are used. Another reason is that it is possible to obtain objective data, so that it is not possible to have incorrect self-perception, and therefore to achieve one’s goals without the help of a neutral second party. This also ties into the use of wearable devices in the field of medicine, where they are used by doctors to get objective data about the patients' daily activity.
We want to note that the line between health and fitness cannot be sharply drawn, as fitness is an integral part of physical and mental health.
These devices collect digital data, which allows improved data flow between doctors, health insurers and patients. In 2015 the German law E-Health-Gesetz introduced the ”elektronische Patientenakte” or ”elektronische Gesundheitsakte” (electronic patient/health file). It should store all the relevant health data for easier access. This push for digital information in health is also supported by insurers. Jens Baas, the principal member of the management board of the German health insurer Techniker Krankenkasse, predicts that in the future doctors will have full access to data of fitness trackers.[31]
Devices
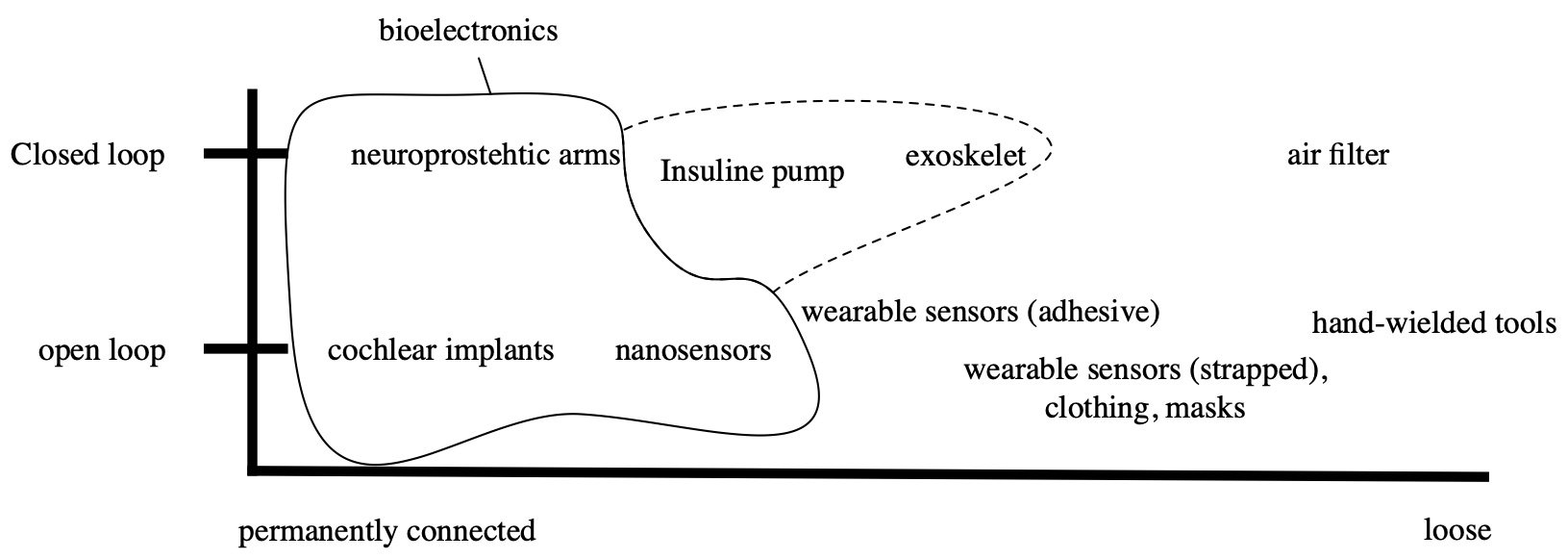 Wearable health technology ranges from loosely connected to operationally implemented. They are used to record data or interact with the body. All wearable medical and fitness devices have in common that human faculties are enhanced by this technology in one way or the other.
One affordable way of achieving this is by devices with the sole functionality to record specific medical data of the user. The intention is that the user or their doctor can get health parameters, to then adjust behavior or the used treatment (e.g. medication). Similarly, fitness trackers are used to record the activity of the wearer so that the user gets a better understanding of their fitness. They can also use these tools to compete against the records of other people, which can help to motivate the user.
Wearable health technology ranges from loosely connected to operationally implemented. They are used to record data or interact with the body. All wearable medical and fitness devices have in common that human faculties are enhanced by this technology in one way or the other.
One affordable way of achieving this is by devices with the sole functionality to record specific medical data of the user. The intention is that the user or their doctor can get health parameters, to then adjust behavior or the used treatment (e.g. medication). Similarly, fitness trackers are used to record the activity of the wearer so that the user gets a better understanding of their fitness. They can also use these tools to compete against the records of other people, which can help to motivate the user.
Some wearable devices actively change the environment (i. e. here the body) where parts of the environment are fed back into the device. These are called closed-loop systems. Some devices are operationally connected to the body (bioelectronics) e.g. neuroprosthetics like cochlear implants. Other devices are only attached with a band or adhesive tape and others use a combination of methods (e.g. a passive nanosensor under the skin, transmitter outside the body). It is a matter of debate whether exoskeletons are considered wearables, as they are worn and can be taken off, but because of their size, could form another category. Exoskeletons can even be connected to the nervous system. Closed-loop systems are often used to reduce the effects of disabilities. In these use-cases, they are called assistive technology. However, some devices can be used to further improve the abilities of able people.
 A user who uses machine parts to adjusts their body to their needs can be called a cyborg (cybernetic organism). A cyborg is the connection between man and machine in a self-organizing way. Cyborgs are ubiquitous in our society, but mostly hardly visible. Cyborgs do not have special legal status. Cyborg machine parts are considered property and not body parts in most jurisdictions. Damage to assistive technology or upgrades is therefore considered property damage. The Cyborg Foundation proposed a bill of rights to improve the legal status of cyborgs.[33]
A user who uses machine parts to adjusts their body to their needs can be called a cyborg (cybernetic organism). A cyborg is the connection between man and machine in a self-organizing way. Cyborgs are ubiquitous in our society, but mostly hardly visible. Cyborgs do not have special legal status. Cyborg machine parts are considered property and not body parts in most jurisdictions. Damage to assistive technology or upgrades is therefore considered property damage. The Cyborg Foundation proposed a bill of rights to improve the legal status of cyborgs.[33]
There are also medical devices that are not connected to the body. One instance are sleep trackers, which are attached to the mattress of the sleeping individual. Future developments may allow more unattached devices that take measurements of the body using optical sensors.
Data Transmission
 At some point, the data collected by the devices need to be processed and made visible. Because the devices are so small, it makes sense to transmit the data to another device which provides a (bigger) display and more processing power. Transmissions via a cable are very secure because physical access to the devices or the cable itself is needed. Cables are however cumbersome and sometimes impractical or impossible to use (e.g. passive blood sugar sensor in body, transmitter outside the body) and are therefore seldom utilized.
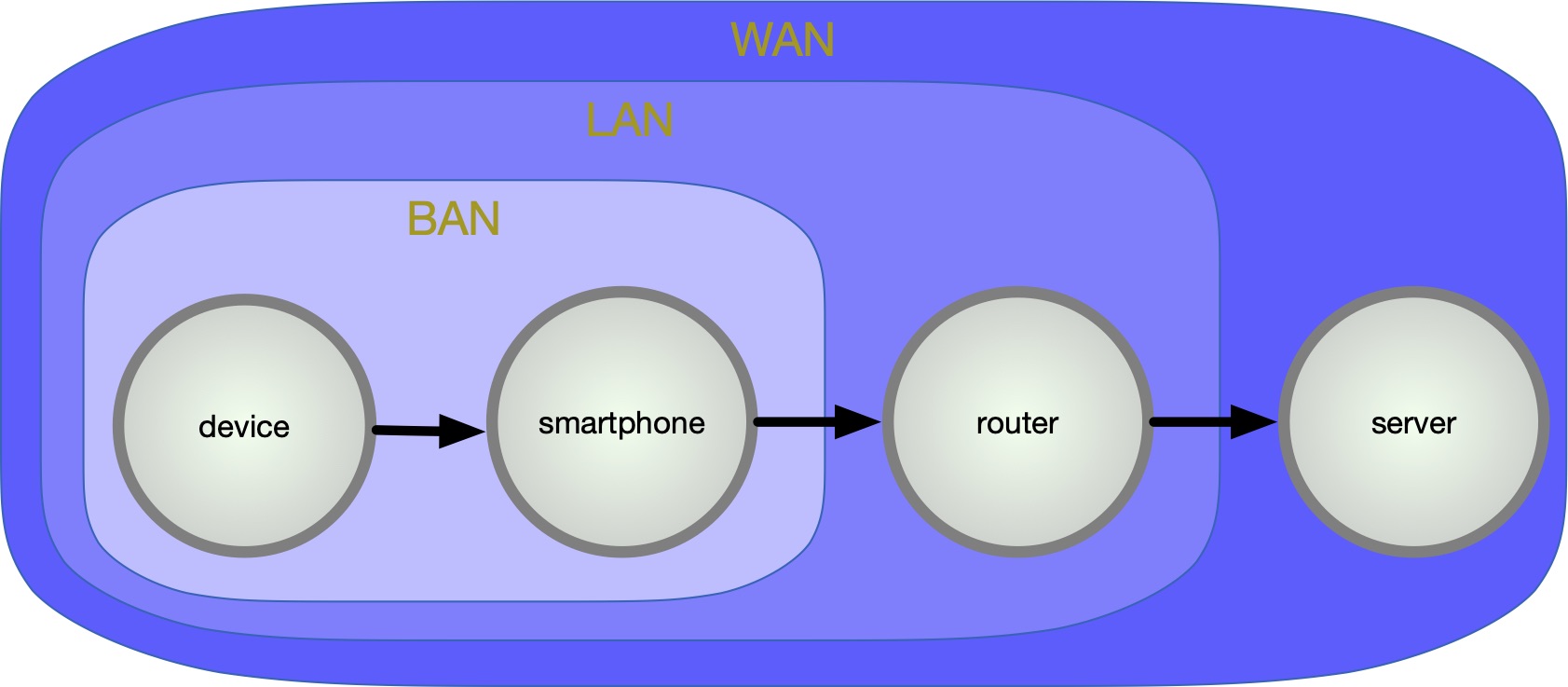
To solve this, many different wireless transmission protocols have been developed which are based on electromagnetic waves. The most prominent protocols are WiFi, NFC or Bluetooth. The network of the devices which are worn by a person on their body is called ”body area network” (BAN), or sometimes ”wireless body area network” (WBAN)[30].
Internet connections via WiFi are commonly used to transfer the collected data to a server for further storage and computation. WiFi is usually encrypted with Wi-Fi Protected Access II (WPA2), but can -since 2018- sometimes be encrypted with WPA3. Using a technology called TKIP (Temporal Key Integrity Protocol), unique encryption keys for each wireless client are created. Those encryption keys are constantly changed. By adding an integrity-checking feature, WPA also ensures that the keys have not been tampered with[5].
Near field communication (NFC) is a communication protocol based on RFID (radio frequency identification) that allows transmissions at low rate bit rates. NFC protocols establish a connection between two NFC-able devices within 4cm of each other.
The transmitted data is dynamically encoded using a secret key.
Most fitness wearables on the market use Bluetooth Low Energy (BLE), which is part of Bluetooth 4.0 and onwards, to connect to a nearby device with more computing power (mainly smartphones) than the wearable itself [24]. The RF transceiver (or physical layer) used for a Bluetooth connection operates in the unlicensed ISM band centered at 2.4 gigahertz (the same range of frequencies used by microwaves and Wi-Fi). The core system employs a frequency-hopping transceiver to combat interference and fading[14]. To establish a Bluetooth connection, one device needs to be scanning for inquiries, the other needs to actively send an inquiry to the specific device, which will then need to accept the connection. Since Bluetooth 2.1, the Bluetooth connection is being encrypted using a common shared ”Link Key”, using Secure Simple Pairing (SSP)[8].
Many companies offer services where the data of their devices leave the BAN and is transmitted over a router (local area network, LAN) into the wide area network (WAN) to the companies’ server (Fig. 2). Each network is prone to different attack vectors. Following the new ”General Data Protection Regulation” of the EU, which shows effects all around the globe, data is supposed to get more protection. For example, following GDPR Art. 32, all personal data must be encrypted during transmission [10]. Usually, data is encrypted using the Transport Layer Security protocol (TLS).
At some point, the data collected by the devices need to be processed and made visible. Because the devices are so small, it makes sense to transmit the data to another device which provides a (bigger) display and more processing power. Transmissions via a cable are very secure because physical access to the devices or the cable itself is needed. Cables are however cumbersome and sometimes impractical or impossible to use (e.g. passive blood sugar sensor in body, transmitter outside the body) and are therefore seldom utilized.
To solve this, many different wireless transmission protocols have been developed which are based on electromagnetic waves. The most prominent protocols are WiFi, NFC or Bluetooth. The network of the devices which are worn by a person on their body is called ”body area network” (BAN), or sometimes ”wireless body area network” (WBAN)[30].
Internet connections via WiFi are commonly used to transfer the collected data to a server for further storage and computation. WiFi is usually encrypted with Wi-Fi Protected Access II (WPA2), but can -since 2018- sometimes be encrypted with WPA3. Using a technology called TKIP (Temporal Key Integrity Protocol), unique encryption keys for each wireless client are created. Those encryption keys are constantly changed. By adding an integrity-checking feature, WPA also ensures that the keys have not been tampered with[5].
Near field communication (NFC) is a communication protocol based on RFID (radio frequency identification) that allows transmissions at low rate bit rates. NFC protocols establish a connection between two NFC-able devices within 4cm of each other.
The transmitted data is dynamically encoded using a secret key.
Most fitness wearables on the market use Bluetooth Low Energy (BLE), which is part of Bluetooth 4.0 and onwards, to connect to a nearby device with more computing power (mainly smartphones) than the wearable itself [24]. The RF transceiver (or physical layer) used for a Bluetooth connection operates in the unlicensed ISM band centered at 2.4 gigahertz (the same range of frequencies used by microwaves and Wi-Fi). The core system employs a frequency-hopping transceiver to combat interference and fading[14]. To establish a Bluetooth connection, one device needs to be scanning for inquiries, the other needs to actively send an inquiry to the specific device, which will then need to accept the connection. Since Bluetooth 2.1, the Bluetooth connection is being encrypted using a common shared ”Link Key”, using Secure Simple Pairing (SSP)[8].
Many companies offer services where the data of their devices leave the BAN and is transmitted over a router (local area network, LAN) into the wide area network (WAN) to the companies’ server (Fig. 2). Each network is prone to different attack vectors. Following the new ”General Data Protection Regulation” of the EU, which shows effects all around the globe, data is supposed to get more protection. For example, following GDPR Art. 32, all personal data must be encrypted during transmission [10]. Usually, data is encrypted using the Transport Layer Security protocol (TLS).
Data storage on servers
The General Data Protection Regulation of the EU obliges companies to report data breaches to authorities. However, they can not be held liable for a data loss. Users also have the option to see stored data. This is often not yet implemented in the intentions of the law, and companies that profit from the data try to use dark patterns to confuse the users. This can lead to conflicts with the law [12].
The users of a product are generally willing to accept everything that is needed to be able to use a product. Therefore a special treatment of health data under GDPR Art. 9 does not affect the use of health data, because the users will ”give explicit consent” to the (mis-)use of their data in order to be able to use the device.
The data itself is often stored in cleartext on the companies servers. An option to avoid this is to use end-to-end encryption, so no one other than the person having the private key can read the data. Then the only viable option is that companies can offer their cloud-based backup solutions, however, if the private key is lost, the data can not be accessed anymore.
Chances
Wearable devices have enabled us to keep track of our health and general activity. By recording and reporting activities like sleep patterns, calorie intake, and steps taken, fitness tracking devices play an important role in educating and motivating people to live healthier [39]. For example, in the health company Cigna’s fitness tracker program, 80 % of asked participants stated that they were more motivated to manage their health. Of these participants, 43% were more likely to meet their fitness and health goals [27].
Wu et al. also points out that wearable devices can motivate individuals to form healthy habits[39]. Wu et al. point out that there are 3 major factors in helping habit formation using wearable devices:
- Connection between people and their health: By focusing on overall wellness instead of particular health indicators, long term user engagement with the device can be formed.
- Intelligent assistance: Tips on how to exercise and eat better are the number one information that users want from their devices. Therefore they should provide both convenience and utility.
- Social Motivation: By making the user's goals and progress visible to a group or audience, users will be highly likely to be more committed to reaching their goal. Offering services to share the data of the user and allowing them to join communities with other users, who also share their data, can lead to higher motivation of the user.
This motivation is also not only short-lived like the fitness-studio-membership purchased every new-years. In a study by PatientsLikeMe, patients with multiple sclerosis were given Fitbit One tracking devices and instructions on using the trackers, as well as on sharing data to PatientsLikeMe’s online discussion platform. The motivation of the participants was reportedly continually high with an adherence rate of 87%. After the study, 83% of participants were so motivated and convinced of the benefits, that they reported continuing to use the device after the end of the study [9].
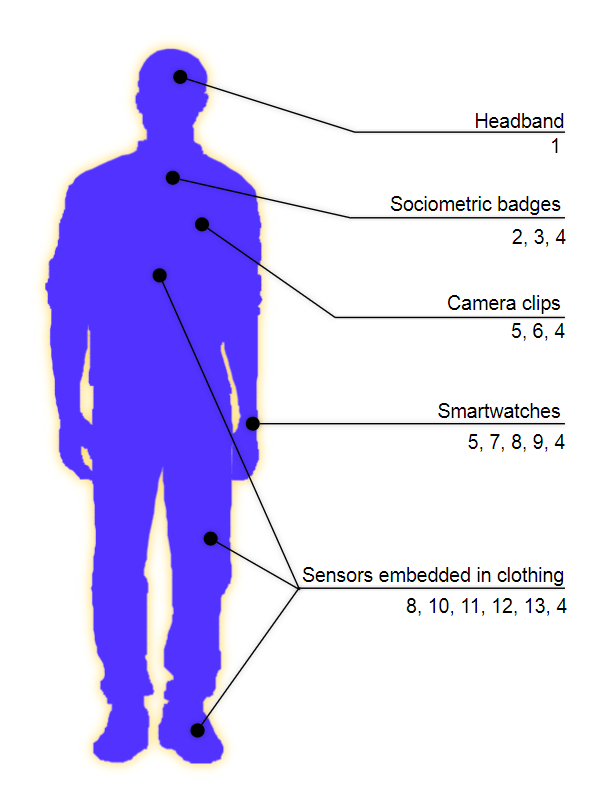
This leads us to the benefits of wearables in medical practice and research. As illustrated in Figure 3, wearables can offer a lot of insight into the human body via a multitude of sensors and a broad range of parameters: ”Heart rate can be measured with an oximeter built into a ring, muscle activity with an electromyographic sensor embedded into clothing, stress with an electrodermal sensor incorporated into a wristband, and physical activity or sleep patterns via an accelerometer in a watch. In addition, a female’s most fertile period can be identified with detailed body temperature tracking, while levels of mental attention can be monitored with a small number of non-gelled electroencephalogram (EEG) electrodes. Levels of social interaction (also known to affect general well-being) can be monitored using proximity detection to others with Bluetooth- or Wi-Fi-enabled devices.” [28]
But even with just a smartphone, many specialized and costly devices can be replaced. According to Agu et al. [3], even smartphones released as early as 2012 can be used to substitute several classical medical devices and procedures, without the need for huge investments in money or time.
Using the smartphone's microphone, diseases like asthma, chronic obstructive pulmonary disease (COPD) and cystic fibrosis can be diagnosed, analyzing various factors like the integration of airflow rate, replacing a portable spirometer, which can cost up to 4000$ [19, 20].
The smartphone's microphones can also be used in cough detection, which plays a big role in a wide range of ailments, from the common cold to allergies, bronchitis, asthma, pneumonia, tuberculosis and even lung cancer. This is achieved by recording coughs of a patient and analyzing the "explosive expiration phase" using multiple machine learning classifiers.
Very expensive Silhouette Wound Assessment Systems can be replaced by a smartphone as well. These devices are used to monitor the wound-development of (diabetic) patients’ (chronic) wounds, by imaging, measuring and documenting the wound, in order to help doctors get an overview of the effects of their treatment of the patient. As shown in a study by Wang et al. [37], by developing an app for diabetics to check the healing status of their wounds, wound assessment systems that can cost up to 6450$ can be replaced, using self-made images of the wound, which are then analyzed using the level set segmentation algorithm and color segmentation using k-means clustering.
Various ailments of the respiratory tract, such as Allergic rhinitis can be classified and analyzed using audio recorded by the smartphone. Nan- Chen et al. [6] used an audio recognition machine learning framework to filter out unwanted and unnecessary noise from the recorded audio, which is then transferred to a server. On the server a Support Vector Machine (SVM) machine learning framework is then used to analyze and classify the audio, to detect ailments of the respiratory tract.
Using the smartphones accelerometer or a video-feed recorded by the camera of the smartphone, even classic medical devices for heart rate detection, blood pressure and blood oxygen saturation like the ECG or EKG (up to 5000$) can be replaced by a much cheaper alternative that is already available to the patient. Using a technique called ”Photoplethysmography”, the heart rate of a patient can be measured by tiny, but recordable differences in the reflection of light off of certain areas of the body. Because more blood is pumped into their face [29], finger [21, 22] or earlobe, the corresponding body part is less reflective. This change in reflection can then be used to measure the person’s heartbeat, which is the cause of the measured change [3].
Even the personal diagnosis by a dermatologist can be replaced using images of suspicious lesions to detect melanoma, which is the most lethal type of skin cancer, causing over 75% of skin cancer related deaths[17]. By comparing patterns in images of suspicious lesions with a library of images of cancerous skin, Wadhawan et al. [35] could detect melanoma with a smartphone app. They used a widely used set of pattern-matching criteria, that are used by dermatologists for the same purpose called the ”7-point checklist”.
In another study by Chen et al. [7] an ELM- based learning method was used to gather social information about a user from dynamic Bluetooth data. Using this in conjunction with data about the user’s physical activity and sleep duration, measured using a wearable wristband and a smartphone app, it is possible to identify the severity of symptoms of depression, drastically helping the user to find the right medication, which is very difficult without an intrusive 24-hour observation [23].
Sleep disorders like sleep apnea, where the patient ceases to breathe for a few seconds to a few minutes, can also quickly be diagnosed with a lightweight wearable measuring heart rate, breathing volume and snoring, measured through tissue vibration[16]. This increases sleep quality, as it can be done without the use of a heavy and costly polysomnograph in the comfort of the patient's home. As sleep apnoea is often only ”diagnosed” by a family member and not the patient itself, the use of wearable medical devices can lead to a higher detection rate, enabling the patient and his family to detect the ailment themselves.
These examples clearly show the chances and benefits of using wearable medical devices:
- Health Benefits: Wearable devices can significantly help in detecting ailments and in staying healthy by increasing motivation and improving a regular fitness regimen.
- Monetary Benefits: Wearable medical devices are significantly cheaper than traditional devices while often attaining the same quality.
- Time Benefits: By using wearable devices, the user saves the time to go to the doctor or a fitness center.
Combining these benefits and keeping in mind that wearable devices use already existing technology and the same protocols that are being used to transfer all kinds of personal data, like mobile or online payment, where the users bank information is transmitted the same way medical data is transmitted with wearable health devices, these benefits can clearly be regarded as a good and valuable improvement in the users life and health. However, even if the technology used in the transfer and storage of data generated by wearable devices is commonly used in other products and services, there is no guarantee that these technologies are safe.
Risks and Ethical Problems
Altering the body or its capabilities is a matter of controversy for some communities[36]. Should it be embraced or rejected? Is there a line to draw? Assistive technology was often quickly normalized in culture. Examples are glasses, vaccines, and prosthetics. People tend to draw a moral line where technology grants super-human possibilities. Enhancing the body with super-human abilities is a step into the direction of homo sapiens becoming techno sapiens. Whether this is something to embrace or reject is a question of ideology or religion. The techno logic view[11] sees the world as problems, which are to be solved by technology. In the transhumanistic view, the body is another problem which is valued as something weak and which needs to be overcome. This belief that the body has to be overcome is a means in some gnostic religions, where the ultimate goal is to become god again[38] (cf. ”homo deus” [15]). Societies usually consist of similarly-abled people. Exceptions are physically disabled people where these tools are used in medical therapy to bring their levels of ability to the ones of healthier people. Wearables can improve human faculties and therefore increase the range of body-derived power distributed in society. Wallach argues that this undermines social cohesion. Empathy works because I know that other humans’ experience is similar to mine. Our perception is based on our body and its faculties[32]. When our perception differs a lot, our interpersonal shared reality diverges. Therefore, this makes empathy and could isolate people. Not everyone wants to or can be part of these enhancements. The first consequences can be observed today, where especially older people do not have the finances, skills or even the will to use digital devices and services. Normalization can also create the problem that individuals are pressured to use these enhancements against their will. The German health insurer AOK grants a bonus to people who have good enough data in their fitness record (Apple Health or Google Fit)[4]. The US insurer Aetna reportedly collaborates with Apple to give users personalized health advice based on the data of the apple watch[2]. They also advertise with quasi-monetary benefits for using the app like gift cards from shops. For the user this makes not using fitness trackers more expensive, therefore discriminating against people that cannot afford themselves these fitness devices, or that don’t want to afford them because of ethical and privacy related considerations.
Being medical data, the transferred and stored data is the most intimate of all data. Because with wearable medical and fitness devices, data on individuals is generated, this data can cause ethical issues as it can be used against the user. These problems are general in nature. One problem is the recording of historical data, so it is possible to derive which activities an individual performed in the past, allowing to create a profile of the user and his activity. Our society is built upon humanistic values such as individualism. Individualism needs controlled data access to keep up information asymmetry. Bad access control can create transparency. Viewed from the perspective of game theory, transparency removes information asymmetry which weakens the individual. Offering such tools is therefore questionable because the individual is tricked into believing that it can keep up the information asymmetry, while in reality the information asymmetry is weakened. As data security cannot be guaranteed, creating, transmitting and storing data is connected to some risk, where companies try to manipulate the perception of this risk. Companies are also not the only actors, as government executives are also interested to remove one-sided information asymmetry from people.
No system is completely secure. Sometimes new vulnerabilities are found for protocols that were considered secure. In 2016 a vulnerability in the WPA2 protocol was published, which allowed attackers to listen to the communication sent via WiFi [25]. This could be solved by updating the patches of the manufacturers of the devices. Another example of a system that was considered secure is the Heartbleed-bug in the software OpenSSL. There is no easy way for consumers to see if their devices are properly updated and secured against known attacks.
With the data stored in databases of various corporations, the user does not have direct control over his private data. When the data is stored on the servers in cleartext this bears the risks that the data is accessed by third parties.
In most cases, there is no technical need to transport the data to other servers. Companies are huge beneficiaries when devices are registered to a personalized online account. By analyzing the usage, data companies can get cheap user statistics on how the product is used and by whom. Traditionally, costly user studies had to be performed to obtain that data. The company therefore saves a lot of money by not having to conduct these user studies anymore. Offering software-as-a-service allows companies staying competitive because the software can be changed rapidly and a lot of metrics can be collected. This change from local to required online delivered software should be seen critically from the user perspective because many devices only work with an internet-connected account. The data is therefore personalized available to the companies. When parts of the infrastructure break, the devices are no longer usable, which can lead to major problems. In areas with no (good) infrastructure, these devices cannot be used at all, leading to a geographically based form of discrimination. Companies can also often ban single users from using their accounts without legal reasons for that ban, therefore excluding specific individuals from their benefits.
The risks that the generated data is maliciously used is much higher when the data is transported and stored on external servers as well. As we have seen, normalization effects can pressure individuals to use certain technology. In some cases a product has no alternative, so users can only decide between using a product or service with unethical data usage, or completely abstaining from it and its benefits. Companies know and use this pressure to keep people using their systems. Companies push non-optional and unethical data collection to the edge of society’s acceptable limits, to keep the normalization effect intact.
Another risk of a data connection to the WAN is that the data might be tangled with, to manipulate or harm the user. The user or his or her doctor might change therapy based on false data, which can lead to extremely negative consequences for the user. In extreme cases, this could even lead to the death of the user through the wrong medication.
To prevent the data from leaving the LAN, it would be possible to store the data locally. There are no open source platforms or protocols to self-host central health repositories, however, a simple raw data export option in human or machine-readable or both format (CSV, JSON, XML, etc. ) should be included in the used software to collect the data independently. Based on these formats a visualization can be created with simple tools like spreadsheet programs.
Because many devices actively emit electromagnetic signals, the position tracking of users and their behavior is possible[34]. People usually wear an electromagnetic signal sending smartphone anyways, so additional devices don’t do much additional harm if they are not significantly easier to track.
Conclusion
In conclusion, we can see that wearable medical and fitness devices provide a lot of benefits, but also raise three major ethical problems:
- Security of personal data in transit and storage: To compute, store and compare the user's medical and fitness data, it needs to be sent to servers via WiFi. This leads to a vulnerability in privacy, as the data can be intercepted or tampered with both in transit as well as in storage through security-gaps. This is a problem that exists with all digital data and is a concern in ethics and society as a whole.
- Handling of personal data: As the companies that sell wearable medical and fitness devices often hold the rights to the data created by them, their intent and moral handling of it is an area of ethical concern. Is the company using the data for something the user might not want? Is it giving access to third parties to exploit their users?
- Normalization effects: When technology becomes adopted by many people this can create societal pressure to also use products or services. This pressure can lead to other ethical problems, like discrimination, monopolies, etc.
These problems tie into a broader discussion of privacy and moral handling of data in an ever-digitizing world. The extreme privacy of the generated medical data and the lack of regulation in the field of wearable medical and fitness devices leads to an increased focus on these issues. As these issues are however not specific to wearable medical and fitness devices, but only more severe in this case, it can be said that they do provide an increase in life quality for their users, so long as they are informed about the ethical issues that follow the use of these devices. As transhumanistic ideas are becoming more and more real in the form of these devices, society needs to find answers to the questions on how these devices should or should not be regulated.
Other/Future ethical considerations
In this paper, we have shown the benefits and ethical risks of using wearable medical and fitness devices. However, this field is larger than the scope of this paper, so some issues regarding wearable medical and fitness devices require more research. Also, as technology is progressing at an ever-faster rate, with the use of Artificial Intelligence, robots and an ever progressing digitization, new ethical issues might occur soon. These issues might be:
- The use of AI in medicine and healthcare
- Legal issues
- Regulatory issues in controlling wearable
- medical and fitness devices to ensure consistent quality and therefore reliability
- Mental health effects of using wearable medical and fitness devices (e.g. worsening of conditions of hypochondriac people)
References
- [1] 10 reasons why to use a fitness tracker. url: http://fitnesstracker24.com/10-reasons-why-to-use-a-fitness-tracker/. (accessed: 23.01.2019).
- [2] Aetna Announces Attain, a Personalized Well-being Experience Combining Health History with the Apple Watch. url: https://news.aetna.com/news-releases/aetna-announces-attain-a-personalized-well-being-experience-that-combines-health-history-with-apple-watch-information-to-empower-better-health/. (accessed: 02.02.2019).
- [3] Emmanuel Agu et al. “The smartphone as a medical device: Assessing enablers, bene- fits and challenges”. In: Internet-of-Things Networking and Control (IoT-NC), 2013 IEEE International Workshop of. IEEE. 2013, pp. 48–52.
- [4] AOK PLUS Bonusprogramm Information leaflet. url: https://www.aok.de/pk/fileadmin/userupload/AOK-PLUS/05-Content-PDF / Bonusprogramm - Infosheet - overview-activities-proof-english.pdf.
- [5] Vangie Beal. WPA - Wi-Fi Protected Ac- cess. url: https://www.webopedia.com/TERM/W/WPA.html. (accessed: 24.01.2019).
- [6] Nan-Chen Chen, Kuo-Cheng Wang, and Hao-Hua Chu. “Listen-to-nose: a low-cost system to record nasal symptoms in daily life”. In: Proceedings of the 2012 ACM Con- ference on Ubiquitous Computing. ACM. 2012, pp. 590–591.
- [7] Zhenyu Chen et al. “ContextSense: un- obtrusive discovery of incremental social context using dynamic bluetooth data”. In: Proceedings of the 2014 ACM Interna- tional Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication. ACM. 2014, pp. 23–26.
- [8] Sean Clinchy. How Encryption Works in Bluetooth. url: http://www.fte.com/webhelp/bpa500/Content/Documentation/WhitePapers/BPA600/Encryption/HowEncryptionWorks.htm. (accessed: 24.01.2019).
- [9] Jonah Comstock. PatientsLikeMe inks As- traZeneca deal, studies FitBit use for MS patients with Biogen. url: https://www.mobihealthnews.com/42418/patientslikeme-inks-astrazeneca-deal-studies-fitbit-use-for-ms-patients-with-biogen. (accessed: 23.01.2019).
- [10] Council of European Union. Parliament and Council regulation (EU) no 2016/679. https://eur-lex.europa.eu/legal-content/EN/TXT/HTML/?uri=CELEX:32016R0679&from=EN. 2016.
- [11] Dr. Simon Longstaff AO Dr. Matthew Beard. “Ethical by design: principles for good technology”. In: (2018).
- [12] DSGVO-Versto ̈ße: Frankreich verhängt Millionen-Strafe gegen Google. url: https://www.heise.de/newsticker/meldung/DSGVO-Verstoesse-Frankreich-verhaengt-Millionen-Strafe-gegen-Google-4283765.html. (accessed: 23.01.2019).
- [13] Cameron Faulkner. What is NFC? Every- thing you need to know. url: https://www.techradar.com/news/what-is-nfc/2. (accessed: 24.01.2019).
- [14] Michael Foley. How does Bluetooth work? url: https://www.scientificamerican.com/ article/experts-how-does-bluetooth-work/. (accessed: 24.01.2019).
- [15] Yuval Noah Harari. Homo Deus: A Brief History of Tomorrow. ”Basic Books”, 2016.
- [16] John Harrington et al. “An electrocardiogram-based analysis evaluating sleep quality in patients with obstructive sleep apnea”. In: Sleep and Breathing 17.3 (2013), pp. 1071–1078.
- [17] Anthony F Jerant et al. “Early detection and treatment of skin cancer.” In: American family physician 62.2 (2000).
- [18] Eric C Larson et al. “Accurate and privacy preserving cough sensing using a low-cost microphone”. In: Proceedings of the 13th international conference on Ubiquitous com- puting. ACM. 2011, pp. 375–384.
- [19] Eric C Larson et al. “SpiroSmart: using a microphone to measure lung function on a mobile phone”. In: Proceedings of the 2012 ACM Conference on Ubiquitous Computing. ACM. 2012, pp. 280–289.
- [20] Eric C Larson et al. “Tracking lung function on any phone”. In: Proceedings of the 3rd ACM Symposium on Computing for Devel- opment. ACM. 2013, p. 29.
- [21] Jinseok Lee et al. “Atrial fibrillation detec- tion using a smart phone”. In: Engineering in Medicine and Biology Society (EMBC), 2012 Annual International Conference of the IEEE. IEEE. 2012, pp. 1177–1180.
- [22] Jinseok Lee et al. “Atrial fibrillation detection using an iPhone 4S”. In: IEEE Trans- actions on Biomedical Engineering 60.1 (2013), pp. 203–206.
- [23] W Vaughn McCall. “A rest-activity biomarker to predict response to SSRIs in major depressive disorder”. In: Journal of psychiatric research 64 (2015), pp. 19–22.
- [24] Florina Mendoza et al. “Assessment of Fit- ness Tracker Security: A Case of Study”. In: Multidisciplinary Digital Publishing In- stitute Proceedings. Vol. 2. 19. 2018, p. 1235.
- [25] New KRACK attack breaks WPA2 WiFi Protocol. url: https://www.bleepingcomputer.com/news/security/new-krack-attack-breaks-wpa2-wifi-protocol/.
- (accessed: 23.01.2019).
- [26] Cal Newport. Digital Minimalism - Choosing a Focused Life in a Noisy World. Penguin Random House, 2019.
- [27] Aditi Pai. Cigna shares some data from its wearable device randomized control trial. url: https://www.mobihealthnews.com/46932/cigna-shares-some-data-from-its-wearable-device-randomized-control-trial. (accessed: 23.01.2019).
- [28] Lukasz Piwek et al. “The rise of consumer health wearables: promises and barriers”. In: PLoS Medicine 13.2 (2016), e1001953.
- [29] Ming-Zher Poh, Daniel J McDuff, and Ros- alind W Picard. “Advancements in noncon- tact, multiparameter physiological measure- ments using a webcam”. In: IEEE transac- tions on biomedical engineering 58.1 (2011), pp. 7–11.
- [30] Stefan Poslad. Ubiquitous computing: smart devices, environments and interactions. John Wiley & Sons, 2011.
- [31] Regina Bo ̈nsch; Regina Reckter. “”Wir brauchen schnell eine einheitliche Akte“”. In: VDI Nachrichten 45 (2018).
- [32] Mila Sugovic and Jessica Witt. “Perception in obesity: Does physical or perceived body size affect perceived distance?” In: Visual Cognition 19 (Jan. 2011), pp. 1323–1326.
- [33] THE CYBORG BILL OF RIGHTS V1.0. url: https://www.cyborgfoundation.com/. (accessed: 02.02.2019).
- [34] Geert Vanderhulst et al. “Detecting Human Encounters from WiFi Radio Signals”. In: Proceedings of the 14th International Con- ference on Mobile and Ubiquitous Multime- dia. MUM ’15. Linz, Austria: ACM, 2015, pp. 97–108. isbn: 978-1-4503-3605-5. doi: 10 . 1145 / 2836041 . 2836050. url: http://doi.acm.org/10.1145/2836041.2836050.
- [35] Tarun Wadhawan et al. “Implementation of the 7-point checklist for melanoma detec- tion on smart handheld devices”. In: En- gineering in Medicine and Biology Society, EMBC, 2011 Annual International Confer- ence of the IEEE. IEEE. 2011, pp. 3180– 3183.
- [36] Wendell Wallachh. A dangerous master. ”Basic Books”, 2015, pp. 162–163.
- [37] Lei Wang et al. “Wound image analysis system for diabetics”. In: Medical Imaging 2013: Image Processing. Vol. 8669. Inter- national Society for Optics and Photonics. 2013, p. 866924.
- [38] Franz Wegener. Gnosis in High Tech und Science-Fiction. KFVR, 2009. isbn: 9783931300241.
- [39] Qinge Wu, Kelli Sum, and Dan Nathan- Roberts. “How fitness trackers facilitate health behavior change”. In: Proceedings of the Human Factors and Ergonomics Society Annual Meeting. Vol. 60. 1. SAGE Publi- cations Sage CA: Los Angeles, CA. 2016, pp. 1068–1072.

 I found a mixture of different media the most fruitful for office-related geistarbeit.
For many people - writers are famous for this - the tools of choice are a piece of paper and a pen. I feel limited with a pen and paper in two ways: It limits to sitting in a chair and erasing is not easy. When erasing is not easy, you are limited to writing sentences and graphics of simple shape, thus limiting complexity.
I found that the saying „out of sight, out of mind“ is true to its heart. Therefore I keep current thoughts on whiteboards on walls. I can edit them to include new insights. Once a model is complete I create a digital copy for my archives. Some of the resulting graphics can be found on this blog.
I found a mixture of different media the most fruitful for office-related geistarbeit.
For many people - writers are famous for this - the tools of choice are a piece of paper and a pen. I feel limited with a pen and paper in two ways: It limits to sitting in a chair and erasing is not easy. When erasing is not easy, you are limited to writing sentences and graphics of simple shape, thus limiting complexity.
I found that the saying „out of sight, out of mind“ is true to its heart. Therefore I keep current thoughts on whiteboards on walls. I can edit them to include new insights. Once a model is complete I create a digital copy for my archives. Some of the resulting graphics can be found on this blog.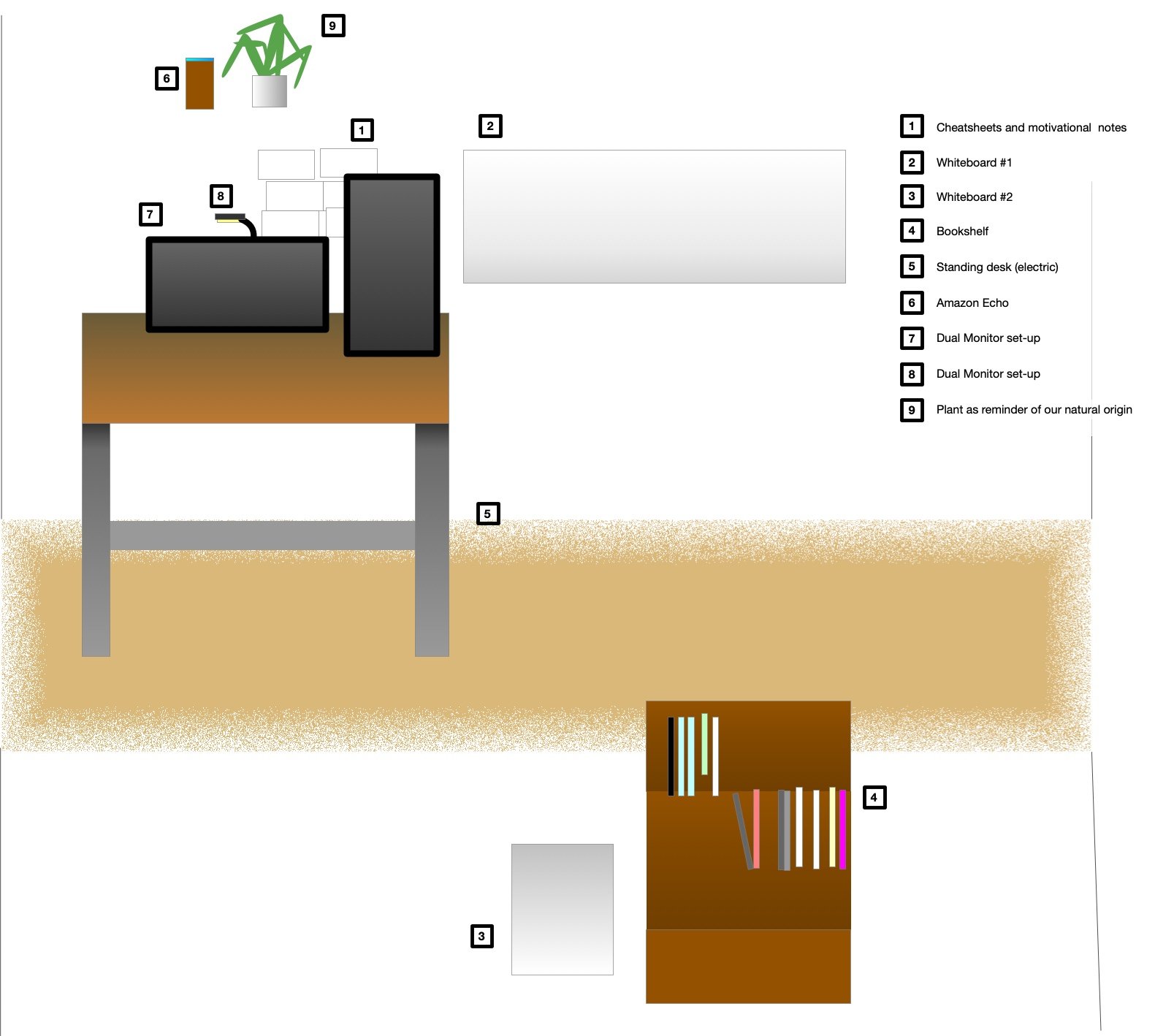 I try to use the concept of spatial arranged information. You can arrange different windows on many screens or just use a huge one. Using the two-dimensional space is useful in many situations but a lot of information is still stored hidden in files. Another issue is that working on some tasks requires a lot of space, so you take a window and arrange it in full width on your main screen. This hides all other windows.
I try to use the concept of spatial arranged information. You can arrange different windows on many screens or just use a huge one. Using the two-dimensional space is useful in many situations but a lot of information is still stored hidden in files. Another issue is that working on some tasks requires a lot of space, so you take a window and arrange it in full width on your main screen. This hides all other windows.