Based on my work on my master thesis I produced a video giving some overview and presenting some discoveries on spiking neural networks. Familiarity with the topic of Artificial Neural Networks is expected.
My last video production was years ago. I noticed that when my workflows were not as productive as I expected it. I exported the keynote presentation and added a voiceover in iMovie. Using only static images is a lot easier to match the VO with the images than timing videos.
The video is based on my thesis defense. Therefore, some previous knowledge might be expected. E.g., I missed mentioning why backpropagation in SNN is not possible (there is no gradient of the activation function).
„You should take a break from work now and eat something. The recipe you wanted is on the display.“ You step up and walk into the kitchen. After having prepared the meal and eaten you step into the room again. „I advice you to meditate now for 20 minutes.“ You take your meditation pillow and sit down. After 20 minutes a sound reminds you to „come back“. „Liz wants to have a beer with you. Should I suggest to meet at 9 at the pub?“. „Yes“, you answer.
The voice is not a real person. It is the speech interface for his digital assistant. The suggestions come from observing his behavior, his calendar, his body, message, habits, and what he instructed. This yet fiction but becoming more and more real.
The world is getting more complex every day. To help us figure out what is important and filter the signals from noise artificial intelligence can be utilized. The chance in these ai systems are to free us from mental energy-draining tasks and bring order into chaos. More and more time is spent on mental tasks managing information, like using a computer (looking things up, analyzing data, configuring systems to get us more insights). Work is increasingly bodyless and happening in human designed environments. A personal AI assistant (paia) can be the assistant for everyone, and reconnect us with our body.
Smart home and paia are inherently connected in the concept of ubiquitous computing. I already analyzed in a previous blog post (German) how the internet changed its „presence“ from gates to the cyberspace to a virtual space-enriching layer of reality. One component of paia is the speech interface. Speech interfaces accelerate the development of paia, as information transmitted over the medium of speech must be condensed to fit into spoken language. A paia has access to personal information. This transforms the ai to a personal assistant. It can also be accessed by any network-connected device which has a display.
Paia are already used by millions of people and use will grow even more. 12% of the people in Germany already have a smart speaker at home¹ and 50% are interested in these devices². Every smart speaker has some form of personal AI assistant (paia). Operating systems like macOS and Windows 10 now come with a speech assistant.
How the internals of such a system work or how it is exactly operated, will not be covered here. We will now look at the prerequisites to build and operate such systems. To operate a paia needs data about you. The data can come from the software you use or data from your smart home. To provide this data to the paia we need
data collecting systems which we can trust and
convenient data interfaces to create a data flow from the source to the assistant.
More data is generated with more and more sensors being installed everywhere (smart home).
The crucial part of the first point is trust. The concerns in these systems are that our privacy should be respected and maintained. But can we trust these systems, when they only work opaquely and sending the data to foreign servers? It does not help the cause of trust that this emerging field is currently controlled by the big tech-feudalistic companies like Amazon or Apple.
To summarize some risks:
Government access (surveillance)
Data gathering companies
Other malicious attackers
Intransparent software
Data leaks
I see a lack of privacy-aware solutions to collect data on yourself. This is something companies, independent developers, citizens or governments can build. Trust in others is not needed if we are in control. Then we only need to trust in ourselves and the inner working of the system.
Furthermore, we, as users, need to be able to trust the judgment of the AI. How can we do this? We need transparency and control. The AI needs to have configurable components or - sticking to the image of a virtual person- we need to be able to teach the obedient AI (see this blog post to see, how this sometimes not the case). The question of who controls our tech is a political one. In the instance of the Amazon Echo system, user control is partially derived by installing „skills“. Skills are like apps for your voice assistant. The problem with that is, that the skill store is another company controlled app store. These app or skill stores enable tech-feudalism. How a company controlled app store can be a problem could just be observed in the case where apple removed the Hong Kong demonstration app from the app store.
The second premise of a paia is a technical one. There needs to be some protocol to create a dataflow. I present a solution utilizing privacy by design for user-generated data in an app.
Most people know the "Echo" by name of "Alexa". Alexa is the default voice activation command. I changed these default configurations to set it that the Echo should be listening whenever I call "computer".
One time I was angry, and when I am angry and alone, I sometimes shout to lower my internal levels of frustration. I interacted with my echo. It was saying more than I wanted so I used a German vulgar version of "Computer, shut up!". The device answered with: "This is not really nice". This reaction was angering me even more. The device was indirectly blaming me. The answer was an attempt to teach me to give it dignity. When people swear at something it is because they feel powerless and swearing is a way to get back power. The user of technology should always be in control. I don't want that a rule-based system has dignity or takes away my power. That is why I called it "computer" and not "Alexa". If you call it "Alexa" it changes the psychology of the interaction. By using a name, you humanize it and give it dignity. If you talk to a virtual person then the response to a swearing makes sense and probably feels right.
This incident showed me another thing. Although you can change the "name" to activate it, the concept behind it does not change. A US company is forcing their values into my home. This is why we need Open Source or fully configurable AI.
I experimented with artificial life and neural networks. Here are the results of my studies and research over the course of the last year. This article is written for a broad audience with an interest in evolution, philosophy and artificial intelligence research.
I store this long list of books I want to read on Amazon and whenever I find that a book is available for little money I buy a copy. This must be what happened as to explain why I obtained that copy of „Artificial Life“ written by Christoph Adami. In the book, the author describes how people developed systems where artificial life developed, wherein some of the universes the emergent species showed intelligent behavior (Polyworld by Larry Yaeger, 1994). The field started with virtual artificial chemistry and advanced to small simulations of nature. I wondered when this was done in the 80s and 90s, why is there not more advanced technology?
Artificial Intelligence needs an environment
Everyone in the area of artificial intelligence research and machine learning is currently looking at deep learning. Probably your interest in the AI topic was also sparked because since recent advances in Machine Learning the field has become very popular. In Deep Learning we stack many layers of neuronal networks and train the network by looking at a function which measures some performance i.e. how well is a certain problem solved. Then some values in the network are changed to optimize this performance function. I never fully believed in deep learning as a way to achieve strong intelligence. You optimize parameters of a function until you get intelligence? And this is all? Because this was not convincing, I looked around to see what other ways are there to build cognitive systems.
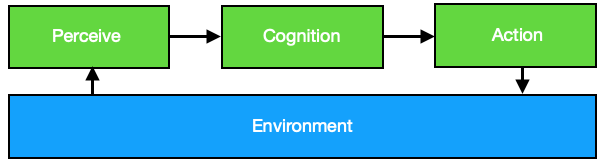
People in the field of neurorobotics believe that intelligence leads to behavior in specific environments. Fogel et al. define intelligent behavior like this: „Intelligent behavior is a composite ability to predict one’s environment coupled with a translation of each prediction into a suitable response in light of some objective”.[1] In Deep Learning the environment is equivalent the dataset. Only the limited dataset is learned and abstracted. When we want to build artificial intelligent systems, we need to talk about cognitive systems; Artificial systems that perceive and act in a closed loop inside a more natural environment.[2]
Information Theory and Life
Adami first describes that it possible to create artificial life. There are several definitions of life. Many of them are outdated because people found organisms which showed that these definitions at hand were too narow. The most convincing theory is based on information theory (termodynamics). Information theory looks at signals and utilizes mathematics to describe the amount of information in a signal. The information which is needed to describe the microstate of a system from the macrostate is measured in what we call entropy. There is also the concept of entropy in thermodynamics. You can argue that they are both the same, so that energy and matter (e=mc²) are equivalent to information. But this is a topic on its own and outside the scope of this article.
Information Theory and Evolution
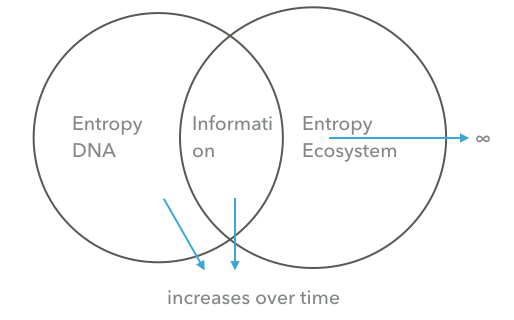
Next, Adami looks at evolution from the perspective of information theory. Evolution does encode information in a system, as the entropy of the environment is shared in the entropy of the contained system. We can build a system where we have genes storing entropy and supporting evolution in a computer.
Here we note that in reality the entropy of the ecosystem, our environment, is infinity. The entropy in our virtual system is not infinite.
You could argue that you could just add a source of entropy by adding a virtual entropy source. The source bubbles random values — entropy. But because there is no principle behind the values it is just noise. In terms of propability theory we call "events" (like a 1 or a 0 appearing) with no connection to another event "conditional independent". Conditional independent noise cannot be encoded in the DNA. Adding conditional independent noise only increases the right part of the diagram.
Entropy Source
We want that the shared entropy, the information, grows in our system over time. The ecosystem should foster the development of intelligent behavior. We further want behavior that is close to human perception. Therefore the ecosystem must be modeled at the level at which we experience reality.
Skipping millions of years
Am I suggesting that the whole human evolution should happen inside the computer? Computers are fast, but they are not that fast, that they can run our history in high detail.
We could try to skip some parts of evolution by utilizing models of systems we understand. We can skip the development of specific cells or the time to develop organs, when we can start with models for body parts.
Unfortunately, we cannot start with a model of a human, because humans are so complex that they only function with development from child to adult during their lifetime.
Phenomena emerge from lower level phenomena. Therefore, we focus on the modeling of the models which are on the same level, we as humans can experience. If we use these high-level description we can skip the time evolution needed for a lot of things.
How to select mating partners
Evolutionary algorithms have one strength compared to other optimizing algorithms. They can optimize without knowing a mathematical description how well a specific goal was performed (objective function). We actually do not want a function which we optimize. The function should be contained implicit in the environment. The virtual animals (agents) who perform well in an environment are selected. The selected parents then bear children. The children get some mutations.
Now we have established the theoretical ground for building a system which should create intelligence.
Prototype
After I did my research and had developed the theory how a system should be build, I built a prototype.
Here is how I built my first prototype:
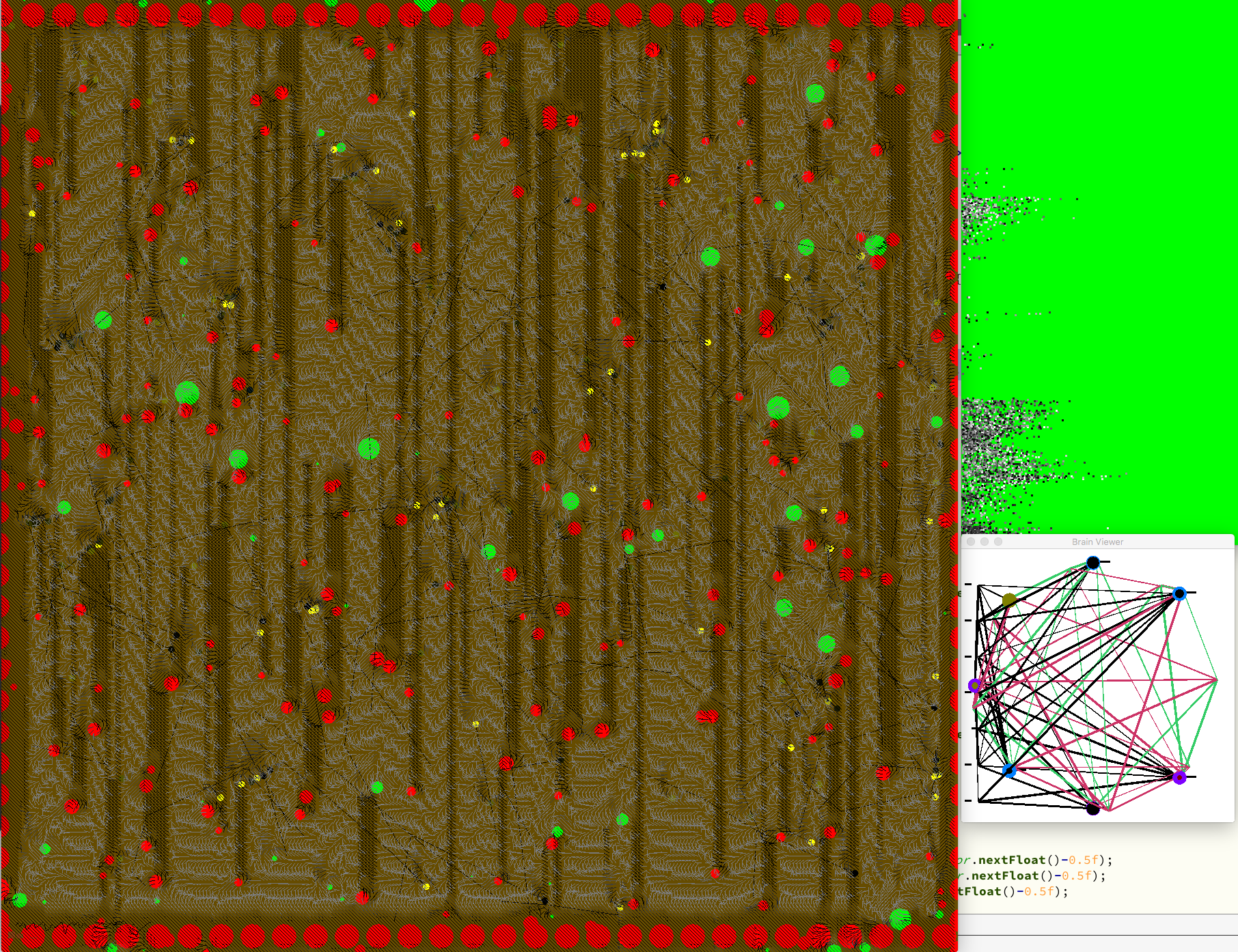
The agents live in a virtual environment (universe). The world contains foods and dangers. The agents can move and once they touch food they eat it and if they touch danger they die.
The agents can sense the surrounding with a sensor like a simplified nose. The nose works by averaging the surrounding environment and dividing by the distance. The nose consists of three channels. One channel for food, one for dangers and one for other agents. They have another input for time and one for their energy level. Inspired by nature I gave them two noses with a small offset to allow stereo sensing.
The outputs are two values for their movement velocity in x- and y-direction.
Between the input and the ouput is the brain. The brain consists of McCulloch-Pitts-neurons. McCulloch and Pitts derived a mathematical model resembling the biological functions (cumulate the weighted input and use some special function, in math notation: o_i=f(\Sum_j w_jO_j)). There are more sophisticated neuron models out there [3]. As the goal is to find the brain and the used phenomena by evolution, a non-limiting topology was used, namely a fully connected brain: In the beginning each neuron is connected with every other neuron. There are no layers. Another specialty is the time discretizing. For each set of input the neuronal network usually creates an output set. Because the neuron activation only propagates to the next neighbors in each time step there is some small delay, as in a real brain. As I wanted to allow that the system can develop loops for something like short term memory in each update step every neuron only propagates to the neighboring neurons. In every update step, a new output is created. The brain could develop to have some delay, so it really needs time to think if longer neuronal paths should be used.
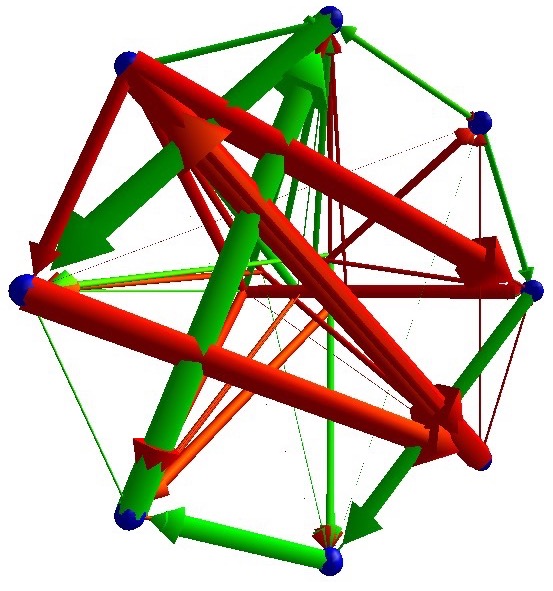
As the purpose of data is not numbers but insights, as Richard Hamming said. I try to use visualization techniques. This is not a trivial task because in this field rarely visualizations are used. Therefore I have to find my own visualization techniques. The picture shows a visualization I made of the brain after some training progress. The neurons are the blue spheres. The colors indicate positive (green) or negative (red) weights in the connections, in biology they are called axons. The size of the neuron indicates the activation at the current time step. In the back are incoming sensory inputs which are connected to every neuron.
One can see that the numbers of neurons are quite small. The number of neurons can be chosen by evolution and it prefers less neurons. Each new neuron also adds a lot of new connections which add a lot of noise. Usually the agents don’t benefit from this added complexity.
Results
After observing the system for a while you can observe steps in evolution. Over a short time a new behavior, or feature, will be developed and replace the old species.
Usually first the species develops moving forward. Later they discover that when you smell danger, that you should turn a little bit or move the other direction. Advanced species walk into the direction the smell of the food.
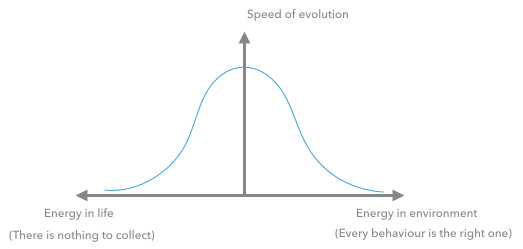
The environment contains an amount of food such that the total amount of energy in the system always stays constant. When more energy is added to the system the reward for finding food is increased and more children can be created. If the energy is very low, the agents have to find a lot of it, therefore making it harder to survive and therefore to evolve. The hurdle for a new evolutionary beneficial step becomes higher. It can happen that the evolution is coming to a halt. We have a value range for the energy, in which the system is evolving. In some sense this behaves like a temperature in chemical or biological processes. We can map the speed of evolution to the parameter and obtain a graph.
Currently this graph shows only a model of what I observed. There is no easy way to measure the speed of information gain in the DNA.
This parameter of energy amount (ea) is not a parameter we are looking to find. We are trying to find the genes from which we get intelligent behavior. The ea parameter says something about the system in which we search for our real parameters. We borrow the name from the field of machine learning and call this ea parameter a hyperparameter. In our system the amount of energy is only one hyperparameter out of many. Another related one is the distribution of the energy ranging from evenly distributed to concentrated on a single point.
What we learn from this is that there are many hyperparameters which must be fine-tuned manually so that virtual agents finds (the best) conditions to develop intelligence.
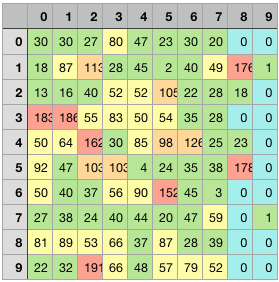
That is no problem, one might say. We just systematically try many hyperparameter values and once we have our values we keep them. In machine learning this is called grid search, because every combination is tested. The picture shows an example of a grid search, where the rows are just different trials with different randomness and the columns different parameters of the energy distribution. One problem is how the success or "fitness" of one run should be measured. I chose the depth of the oldest family tree. This value is depicted if the cell's value.
Another interesting result is that trippy art emerges in the system.
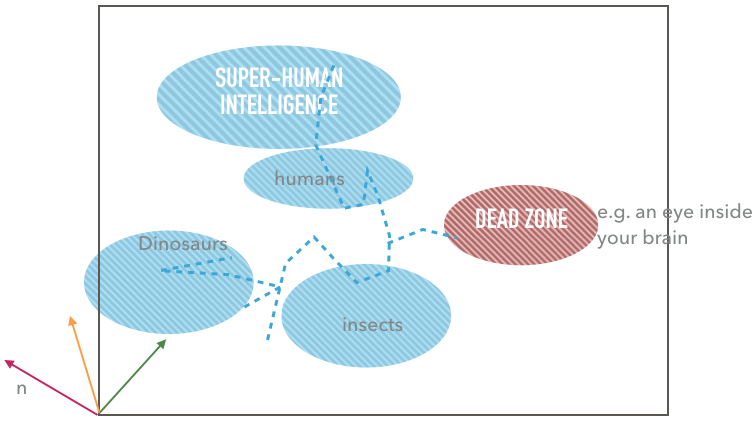
The system does not scale well
The system stops to continue to evolve at a certain point. Evolutionary steps become too hard; the environment is learned by evolution as much as it can. The complexity is too low, so the system gets stuck.
Every DNA has developed relative to the ecosystem. Every genetic encoding can be represented as a point in a high dimensional space (phase space). We cannot modify the environment during a simulation because this is like moving the reference point of the phase space. The system evolves around the hyperparameters we set. They are like constants of our virtual nature. Therefore it does not help if we change them.
Further questions
The more I read about chaotic systems I questioned myself: Is artificial evolution really a chaotic system? To answer this question one has to compute the Lyapunov-exponent, a task which I am still occupied with.
Can we show something as an "edge of chaos" in such a system?
Can we make the evolution open-ended when we find a way to build self-organizing system?
Consciousness needs symbolic representation. Can we support it to develop symbols? Will it start to develop philosophy and religion?
How can we control the AI (alignment problem) when it becomes smart? Can it escape the virtual environment?
Building the system on GPU
On a more additional note, I want to share some thoughts on the computing part. This is probably only interesting for people who are interested in computations.
In my first prototype, I computed the distance of objects based on the position of their center. In my second prototype, the dangers and food are stored in cells. The benefit of using cells is that for the costly sensory computation a kernel can be used. A kernel is a mathematical operation which uses some grid cells. A known size of cells can be cumulated with a mathematical operation to compute the sensory input. This means that we can just use local information to build the whole system. When we use only local information we have a system which is quite close to a cellular automaton. Some scientists argue that our whole universe is built up from a cellular automaton. We could copy the whole memory on the GPU and simulate each cell in a compute shader on the GPU. This means we get a massive performance improvement (maybe like 100 times).



 After I did my research and had developed the theory how a system should be build, I built a prototype.
Here is how I built my first prototype:
The agents live in a virtual environment (universe). The world contains foods and dangers. The agents can move and once they touch food they eat it and if they touch danger they die.
The agents can sense the surrounding with a sensor like a simplified nose. The nose works by averaging the surrounding environment and dividing by the distance. The nose consists of three channels. One channel for food, one for dangers and one for other agents. They have another input for time and one for their energy level. Inspired by nature I gave them two noses with a small offset to allow stereo sensing.
The outputs are two values for their movement velocity in x- and y-direction.
Between the input and the ouput is the brain. The brain consists of McCulloch-Pitts-neurons. McCulloch and Pitts derived a mathematical model resembling the biological functions (cumulate the weighted input and use some special function, in math notation: o_i=f(\Sum_j w_jO_j)). There are more sophisticated neuron models out there [3]. As the goal is to find the brain and the used phenomena by evolution, a non-limiting topology was used, namely a fully connected brain: In the beginning each neuron is connected with every other neuron. There are no layers. Another specialty is the time discretizing. For each set of input the neuronal network usually creates an output set. Because the neuron activation only propagates to the next neighbors in each time step there is some small delay, as in a real brain. As I wanted to allow that the system can develop loops for something like short term memory in each update step every neuron only propagates to the neighboring neurons. In every update step, a new output is created. The brain could develop to have some delay, so it really needs time to think if longer neuronal paths should be used.
After I did my research and had developed the theory how a system should be build, I built a prototype.
Here is how I built my first prototype:
The agents live in a virtual environment (universe). The world contains foods and dangers. The agents can move and once they touch food they eat it and if they touch danger they die.
The agents can sense the surrounding with a sensor like a simplified nose. The nose works by averaging the surrounding environment and dividing by the distance. The nose consists of three channels. One channel for food, one for dangers and one for other agents. They have another input for time and one for their energy level. Inspired by nature I gave them two noses with a small offset to allow stereo sensing.
The outputs are two values for their movement velocity in x- and y-direction.
Between the input and the ouput is the brain. The brain consists of McCulloch-Pitts-neurons. McCulloch and Pitts derived a mathematical model resembling the biological functions (cumulate the weighted input and use some special function, in math notation: o_i=f(\Sum_j w_jO_j)). There are more sophisticated neuron models out there [3]. As the goal is to find the brain and the used phenomena by evolution, a non-limiting topology was used, namely a fully connected brain: In the beginning each neuron is connected with every other neuron. There are no layers. Another specialty is the time discretizing. For each set of input the neuronal network usually creates an output set. Because the neuron activation only propagates to the next neighbors in each time step there is some small delay, as in a real brain. As I wanted to allow that the system can develop loops for something like short term memory in each update step every neuron only propagates to the neighboring neurons. In every update step, a new output is created. The brain could develop to have some delay, so it really needs time to think if longer neuronal paths should be used.